Unreasonable Effectiveness of LLMs for Code Generation
At this point, we are no longer surprised about what language models can do. However, it is still unclear how language models derive such amazing abilities especially in the area of code generation. This blog discusses the highlights from the paper Multilingual Evaluation of Code Generation Models which give some clue as to how LLMs are so great at coding.
Out of Domain Generalization
If we train a model on one programming language, it turns out that such a model can also write code in different programming languages, especially when the model is large enough! Let’s look at the results and sample generations.
Here, we train a decoder model on three languages: Python, Java, JavaScript. We use the model to sample and generate many versions of code and evaluate with the pass@k metric (one can think of it as accuracies given k chances). The result in Figure 1 shows that not only does it perform well on all languages that are trained on, the model also performs well on unseen languages (PHP, Ruby, Kotlin). How is this possible?

Natural Co-Occurrences of Multi-lingual Knowledge
It turns out that the natural occurrences of code data are quite common. Take the following code for example, which is a Python code that has JavaScript wrapped as a string.
This piece of data counts as Python data since it parses the Python interpreter, as well as being from a .py file. We refer to such multi-lingual occurrences of programming languages as knowledge spillver. Such spillover explains why training language models on Python yields a model that can write JavaScript.
The previous result shows the generalization of multi-lingual model trained on three languages. Mono-lingual models can also generalize.

Multi-ligual versus Mono-lingual

Figure 2 represents the results including results comparing multi- and mono-lingual models. There are a lot going on, but let’s break it down.
- We observe that the Python model (pink) has high accuracy in Java and JavaScript evaluation, which makes sense according to the hypothesis that models can pick up knowledge of other languages embedded in the primary language’s code.
- The Java model (blue) and JavaScript model (green) seem to perform quite poorly on Python. We believe it is likely due to the lack of Python knowledge in Java/JavaScript data.
- In the multi-lingual model where we train on Python, Java, JS, we observe the Python performance being very similar to the mono-lingual Python performance. This seems to confirm the above point that there’s little Java/JS knowledge in Python data, which means that in the multi-ligual case, the Python performance will be close to that of the mono-lingual Python model.

- In Figure 3, we also observe that multi-lingual models perform especially better than mono-lingual models in out-of-domain languages.
- All these observations are consistent with the explanations in Figure 4 where the knowledge in other programming languages is aggregated across all knowledge in each language’s training data.
Large Multi-Lingual Models Really Shine
- As observed in Figure 3, one can see that if the model size is large enough, the advantages of multi-lingual training is more drastic.
- On out-of-domain evaluation, large multi-lingual models seem to break out of the log-linear trend, akin to being at a cusp of the sigmoid trend going upward, aka emergent abilities.
Zero-Shot Translation
- We find that language models can also translate code, without being specifically trained to do so.
- This ability extends to a mono-lingual model. For instance, a Java model can translate from Python to Java reasonably well.
- Java to Python is harder for translation with a Java model, since it doesn’t know how to write Python well. However, it understands Python as some level and is able to use it to write a more accurate function.
- In fact, problems that are difficult can become much easier.
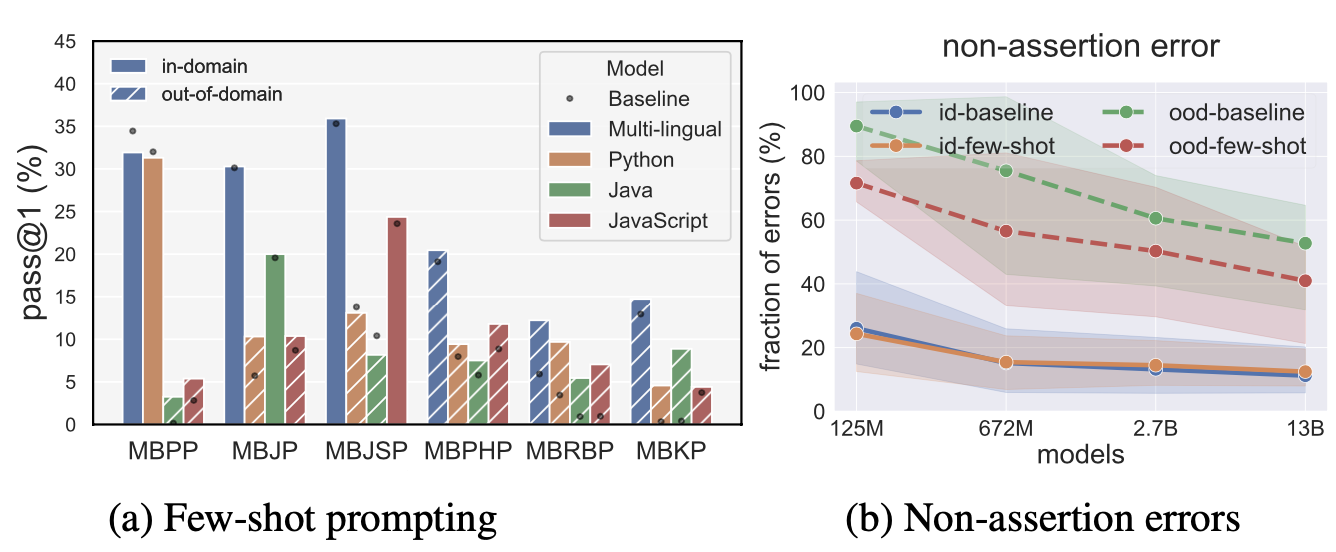
Few-Shot Prompts Helps LLMs on Out-of-Domain Languages
- On out-of-domain languages, the performance can be improved significantly if we give the model few-shot prompts.
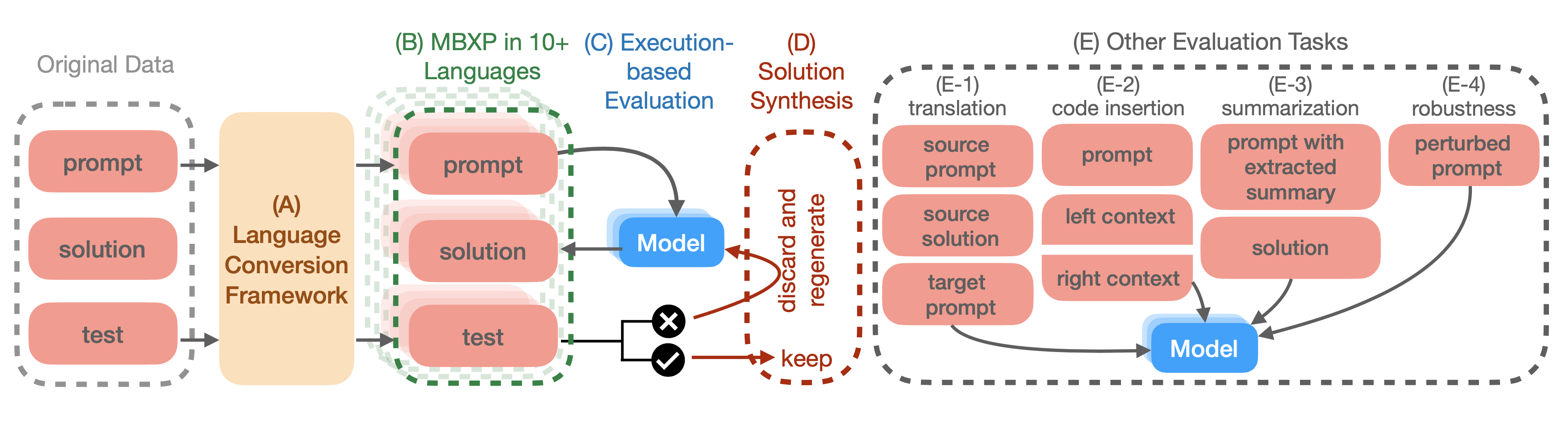
Evaluation Datasets
All of the above analyses require evaluation datasets in different programming languages. In our work Multilingual Evaluation of Code Generation Models, we outlined how we obtain such datasets via transpiling the original HumanEval and MBPP into HumanEvalX and MBXP. We also compose such datasets for different types of evaluation such as Code Insertion evaluation or Code Robustness evaluation.

Appendix
Codex Performance
It is unclear what data and how much the Codex models are trained on. However, a viable guess would be that they’re trained on as much code data as possible with sufficient amount of steps until the performance plateaus.
Below, we show the result of code-cushman-001 and code-davinci-002 for reference. We can observe that the model performs quite well in all languages.
For the evaluation code, see (link to repo).
Table 1: Codex Performance on MBXP and HumanEvalX with pass@1 and greedy decoding.
| code-cushman-001 | code-davinci-002 | |
|---|---|---|
| MBXP | ||
| Python | 58.7% | |
| Java | 45.1% | |
| JavaScript | 46.4% | |
| TypeScript | 46.0% | 58.9% |
| C# | 46.2% | 57.6% |
| C++ | 49.3% | 65.7% |
| Go | 32.7% | 49.2% |
| Kotlin | 44.6% | 60.5% |
| PHP | 44.4% | 60.7% |
| Perl | 34.1% | 44.0% |
| Ruby | 43.7% | 56.3% |
| Scala | 41.9% | 59.8% |
| Swift | 31.3% | 43.5% |
| HumanEvalX | ||
| Python | 46.3% | |
| Java | 32.9% | |
| JavaScript | 28.0% | |
| Typescript | 34.8% | 50.9% |
| C# | 34.8% | 45.3% |
| C++ | ||
| Go | 16.3% | 21.9% |
| Kotlin | 23.0% | 39.8% |
| PHP | 31.1% | 52.8% |
| Perl | 14.9% | 36.0% |
| Ruby | 29.8% | 39.8% |
| Scala | 24.2% | 45.3% |
| Swift | 14.9% | 24.8% |
Unabridged Example of Knowledge Spillover
Below we show a full code snippet of a Python file where JS code is wrapped in a string.
"""Create a Javascript script to encode / decode for a specific encoding
described in a file available at
http://unicode.org/Public/MAPPINGS/VENDORS/MICSFT/WINDOWS/<ENCODING>.TXT
"""
import os
import re
import json
import urllib.request
line_re = re.compile("^(0x[A-Z0-9]+)\s+(0x[A-Z0-9]+)*", re.M)
tmpl = "http://unicode.org/Public/MAPPINGS/VENDORS/MICSFT/WINDOWS/{}.TXT"
encoding = input("Encoding name: ")
req = urllib.request.urlopen(tmpl.format(encoding.upper()))
data = req.read().decode("ascii")
root_dir = os.path.dirname(os.path.dirname(__file__))
libs_dir = os.path.join(root_dir, "www", "src", "libs")
filename = os.path.join(libs_dir, f"encoding_{encoding.lower()}.js")
with open(filename, "w", encoding="utf-8") as out:
out.write("var _table = [")
for line in data.split("\n"):
mo = line_re.match(line)
if mo:
key, value = mo.groups()
out.write(f"{key}, {value or -1},")
out.write("]\n")
out.write("var decoding_table = [],\n encoding_table = []\n")
out.write("""for(var i = 0, len = _table.length; i < len; i += 2){
var value = _table[i + 1]
if(value !== null){
encoding_table[value] = _table[i]
}
decoding_table[_table[i]] = _table[i + 1]
}
$module = {encoding_table, decoding_table}
""")