Ben Athiwaratkun


My name is Ben Athiwaratkun. I am an ML scientist at AWS AI Labs. I completed my PhD in Statistics and focus on machine learning from Cornell University, under the supervision of Andrew Gordon Wilson. Before my PhD, I studied Mathematics and Economics at Williams College.






PhD in Statistics with Special Masters in Computer Science.
Probabilistic FastText for multiple word meanings
Language modeling on machine APIs for malware classification
Mathematics and Economics Double Majors with Honors Thesis in Ergodic Theory.
Optimizing precision of computer-generated phase-regime holograms

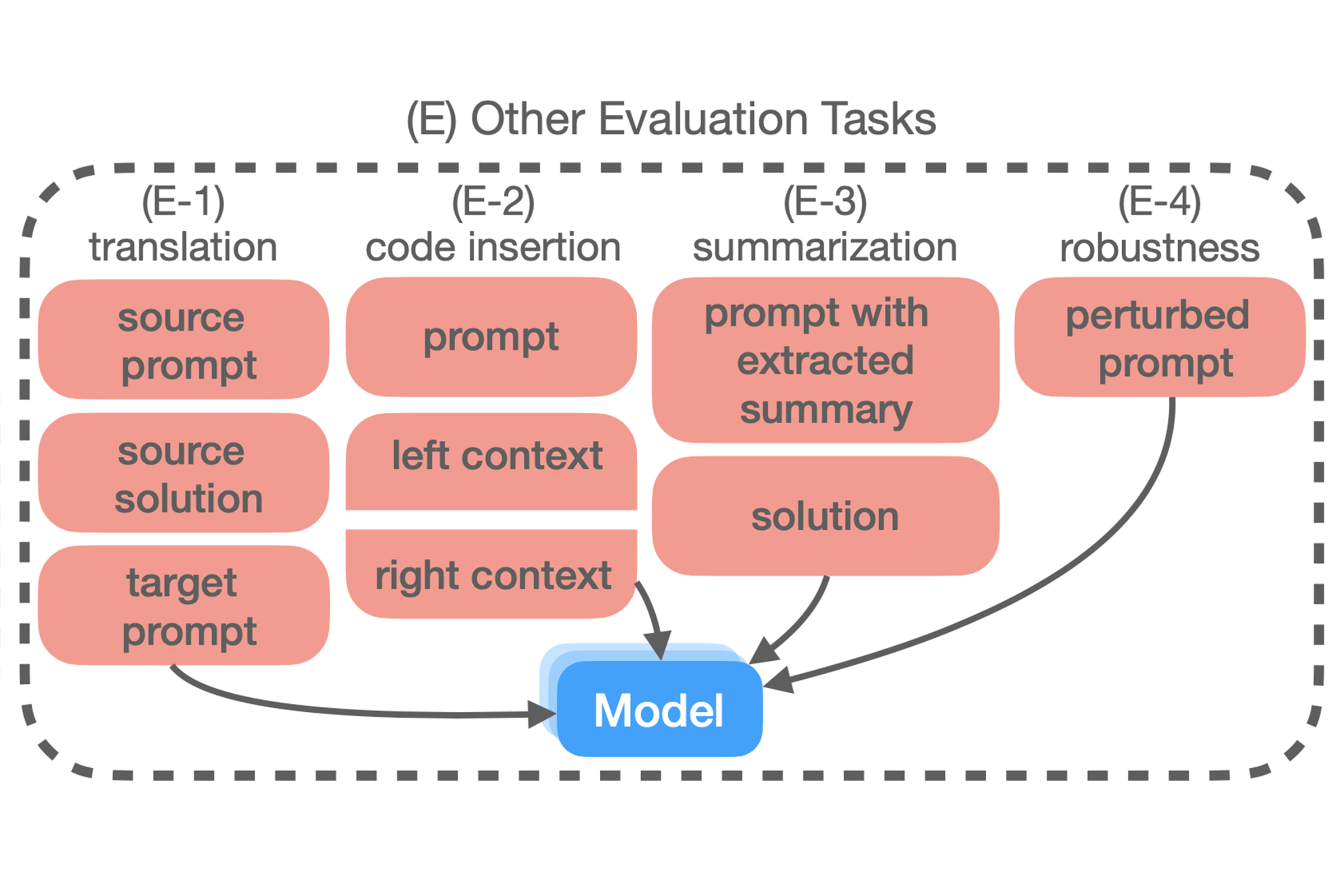
We present MBXP, an execution-based code completion benchmark in 10+ programming languages. This collection of datasets is generated by our conversion framework that translates prompts and test cases from the original MBPP dataset to the corresponding data in a target language. Based on this benchmark, we are able to evaluate code generation models in a multi-lingual fashion, and in particular discover generalization ability of language models on out-of-domain languages, advantages of large multi-lingual models over mono-lingual, benefits of few-shot prompting, and zero-shot translation abilities. In addition, we use our code generation model to perform large-scale bootstrapping to obtain synthetic canonical solutions in several languages. These solutions can be used for other code-related evaluations such as insertion-based, summarization, or code translation tasks where we demonstrate results and release as part of our benchmark.
This repository contains code to perform execution-based multi-lingual evaluation of code generation capabilities and the corresponding data, namely, a multi-lingual benchmark MBXP, multi-lingual MathQA and multi-lingual HumanEval. Results and findings can be found in the paper "Multi-lingual Evaluation of Code Generation Models".
Our paper describes the language conversion framework, the synthetic solution generation, and many other types of evaluation beyond the traditional function completion evaluation such as translation, code insertion, summarization, and robustness evaluation.
Giovanni Paolini, Ben Athiwaratkun, Jason Krone, Jie Ma, Alessandro Achille, Rishita Anubhai, Cicero Nogueira dos Santos, Bing Xiang, Stefano Soatto
We propose a new framework, Translation between Augmented Natural Languages (TANL), to solve many structured prediction language tasks including joint entity and relation extraction, nested named entity recognition, relation classification, semantic role labeling, event extraction, coreference resolution, and dialogue state tracking. Instead of tackling the problem by training task-specific discriminative classifiers, we frame it as a translation task between augmented natural languages, from which the task-relevant information can be easily extracted. Our approach can match or outperform task-specific models on all tasks, and in particular, achieves new state-of-the-art results on joint entity and relation extraction (CoNLL04, ADE, NYT, and ACE2005 datasets), relation classification (FewRel and TACRED), and semantic role labeling (CoNLL-2005 and CoNLL-2012). We accomplish this while using the same architecture and hyperparameters for all tasks and even when training a single model to solve all tasks at the same time (multi-task learning). Finally, we show that our framework can also significantly improve the performance in a low-resource regime, thanks to better use of label semantics.
Ben Athiwaratkun, Cicero Nogueira dos Santos, Jason Krone, Bing Xiang
We propose a generative framework for joint sequence labeling and sentence-level classification. Our model performs multiple sequence labeling tasks at once using a single, shared natural language output space. Unlike prior discriminative methods, our model naturally incorporates label semantics and shares knowledge across tasks. Our framework is general purpose, performing well on few-shot, low-resource, and high-resource tasks. We demonstrate these advantages on popular named entity recognition, slot labeling, and intent classification benchmarks. We set a new state-of-the-art for few-shot slot labeling, improving substantially upon the previous 5-shot (75.0%→90.9%) and 1-shot (70.4%→81.0%) state-of-the-art results. Furthermore, our model generates large improvements (46.27%→63.83%) in low-resource slot labeling over a BERT baseline by incorporating label semantics. We also maintain competitive results on high-resource tasks, performing within two points of the state-of-the-art on all tasks and setting a new state-of-the-art on the SNIPS dataset.
Ben Athiwaratkun, Marc Finzi, Pavel Izmailov, Andrew Gordon Wilson
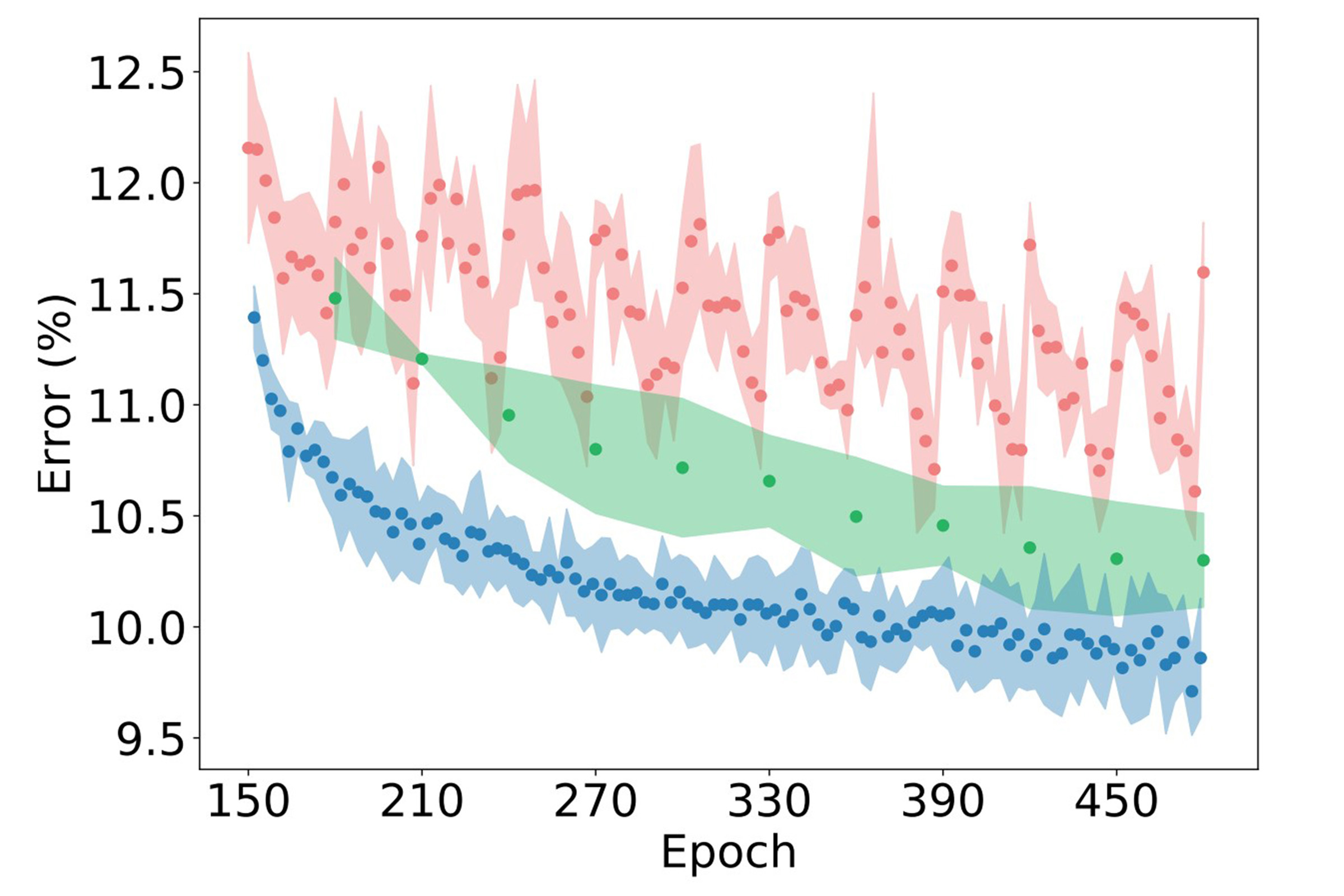
Presently the most successful approaches to semi-supervised learning are based on consistency regularization, whereby a model is trained to be robust to small perturbations of its inputs and parameters. To understand consistency regularization, we conceptually explore how loss geometry interacts with training procedures. The consistency loss dramatically improves generalization performance over supervised-only training; however, we show that SGD struggles to converge on the consistency loss and continues to make large steps that lead to changes in predictions on the test data. Motivated by these observations, we propose to train consistency-based methods with Stochastic Weight Averaging (SWA), a recent approach which averages weights along the trajectory of SGD with a modified learning rate schedule. We also propose fast-SWA, which further accelerates convergence by averaging multiple points within each cycle of a cyclical learning rate schedule. With weight averaging, we achieve the best known semi-supervised results on CIFAR-10 and CIFAR-100, over many different quantities of labeled training data. For example, we achieve 5.0% error on CIFAR-10 with only 4000 labels, compared to the previous best result in the literature of 6.3%.
Ben Athiwaratkun, Andrew Gordon Wilson, Anima Anandkumar
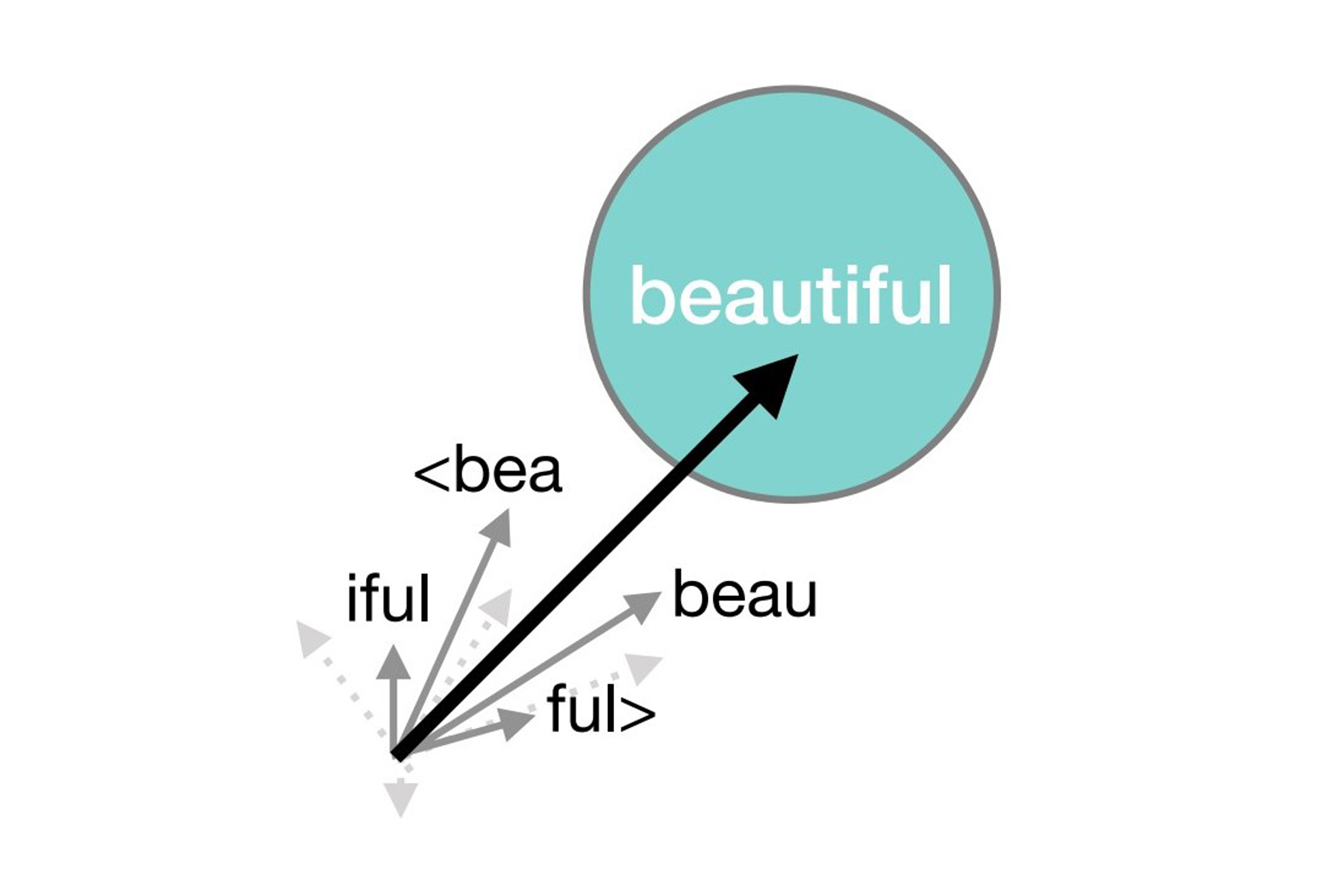
We introduce Probabilistic FastText, a new model for word embeddings that can capture multiple word senses, sub-word structure, and uncertainty information. In particular, we represent each word with a Gaussian mixture density, where the mean of a mixture component is given by the sum of n-grams. This representation allows the model to share statistical strength across sub-word structures (e.g. Latin roots), producing accurate representations of rare, misspelt, or even unseen words. Moreover, each component of the mixture can capture a different word sense. Probabilistic FastText outperforms both FastText, which has no probabilistic model, and dictionary-level probabilistic embeddings, which do not incorporate subword structures, on several word-similarity benchmarks, including English RareWord and foreign language datasets. We also achieve state-of-art performance on benchmarks that measure ability to discern different meanings. Thus, the proposed model is the first to achieve multi-sense representations while having enriched semantics on rare words.
Xilun Chen, Yu Sun, Ben Athiwaratkun, Claire Cardie, Kilian Weinberger
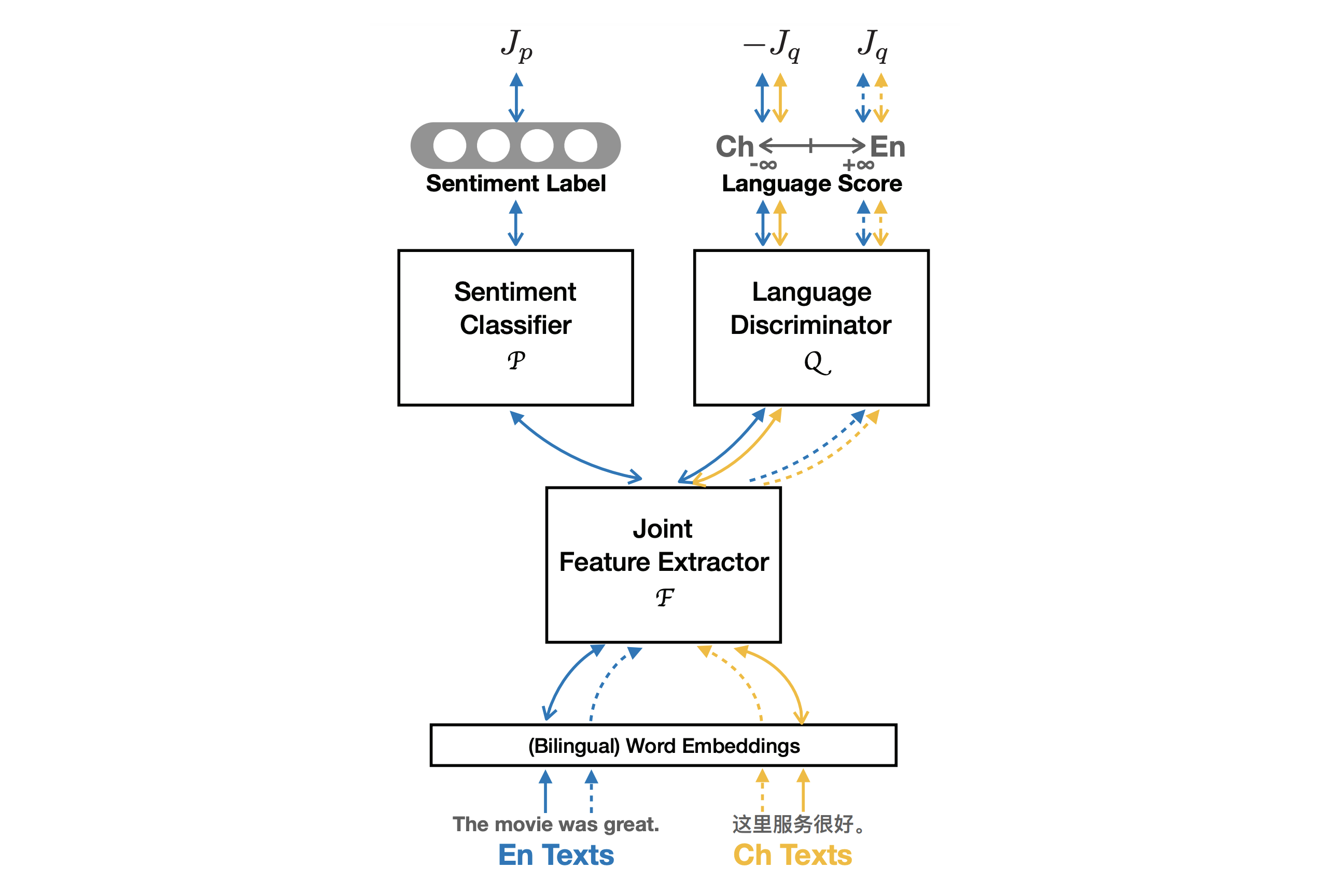
In recent years great success has been achieved in sentiment classification for English, thanks in part to the availability of copious annotated resources. Unfortunately, most languages do not enjoy such an abundance of labeled data. To tackle the sentiment classification problem in low-resource languages without adequate annotated data, we propose an Adversarial Deep Averaging Network (ADAN) to transfer the knowledge learned from labeled data on a resource-rich source language to low-resource languages where only unlabeled data exists. ADAN has two discriminative branches: a sentiment classifier and an adversarial language discriminator. Both branches take input from a shared feature extractor to learn hidden representations that are simultaneously indicative for the classification task and invariant across languages. Experiments on Chinese and Arabic sentiment classification demonstrate that ADAN significantly outperforms state-of-the-art systems.
Ben Athiwaratkun, Andrew Gordon Wilson
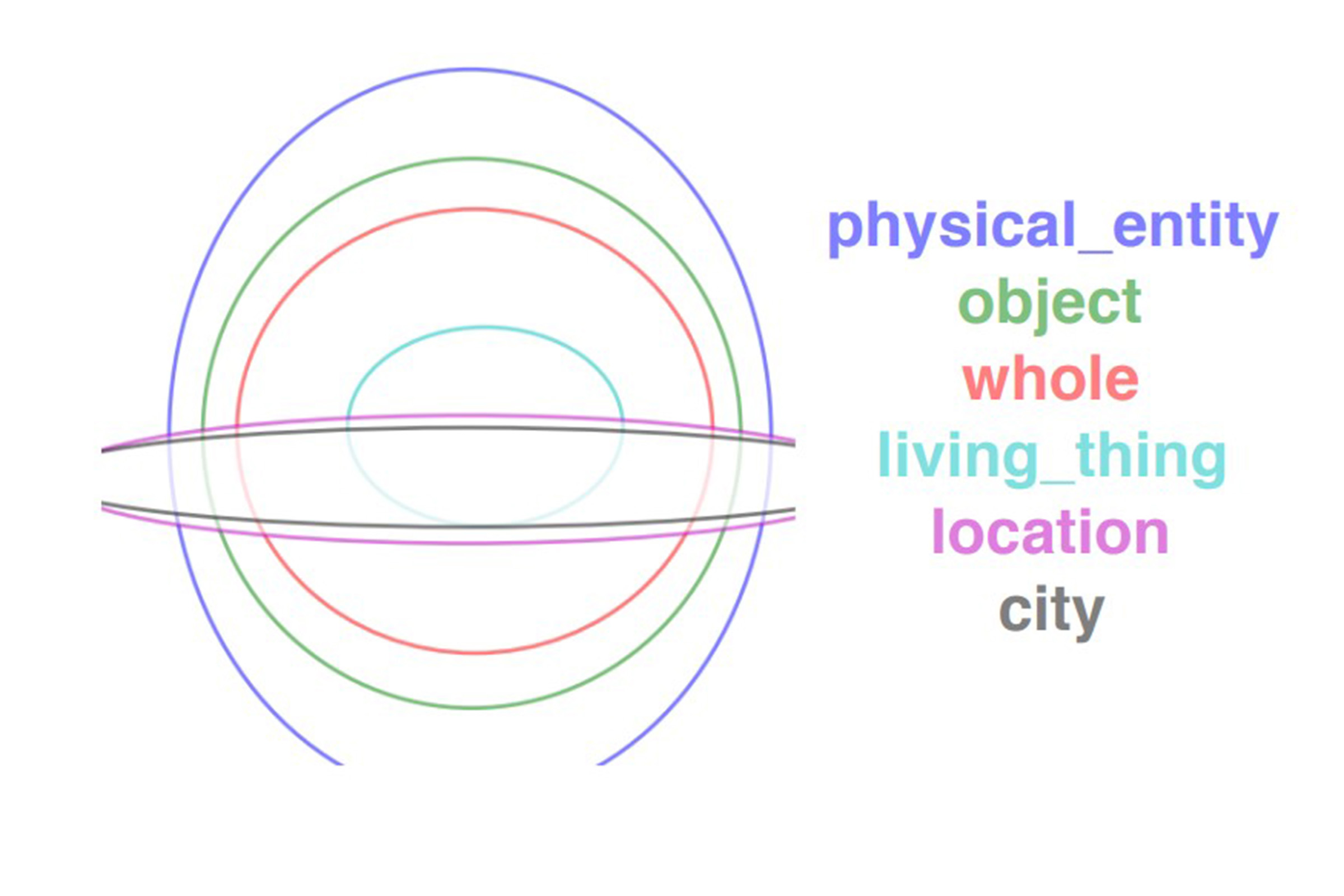
By representing words with probability densities rather than point vectors, probabilistic word embeddings can capture rich and interpretable semantic information and uncertainty. The uncertainty information can be particularly meaningful in capturing entailment relationships -- whereby general words such as "entity" correspond to broad distributions that encompass more specific words such as "animal" or "instrument". We introduce density order embeddings, which learn hierarchical representations through encapsulation of probability densities. In particular, we propose simple yet effective loss functions and distance metrics, as well as graph-based schemes to select negative samples to better learn hierarchical density representations. Our approach provides state-of-the-art performance on the WordNet hypernym relationship prediction task and the challenging HyperLex lexical entailment dataset -- while retaining a rich and interpretable density representation.
Ben Athiwaratkun, Andrew Gordon Wilson
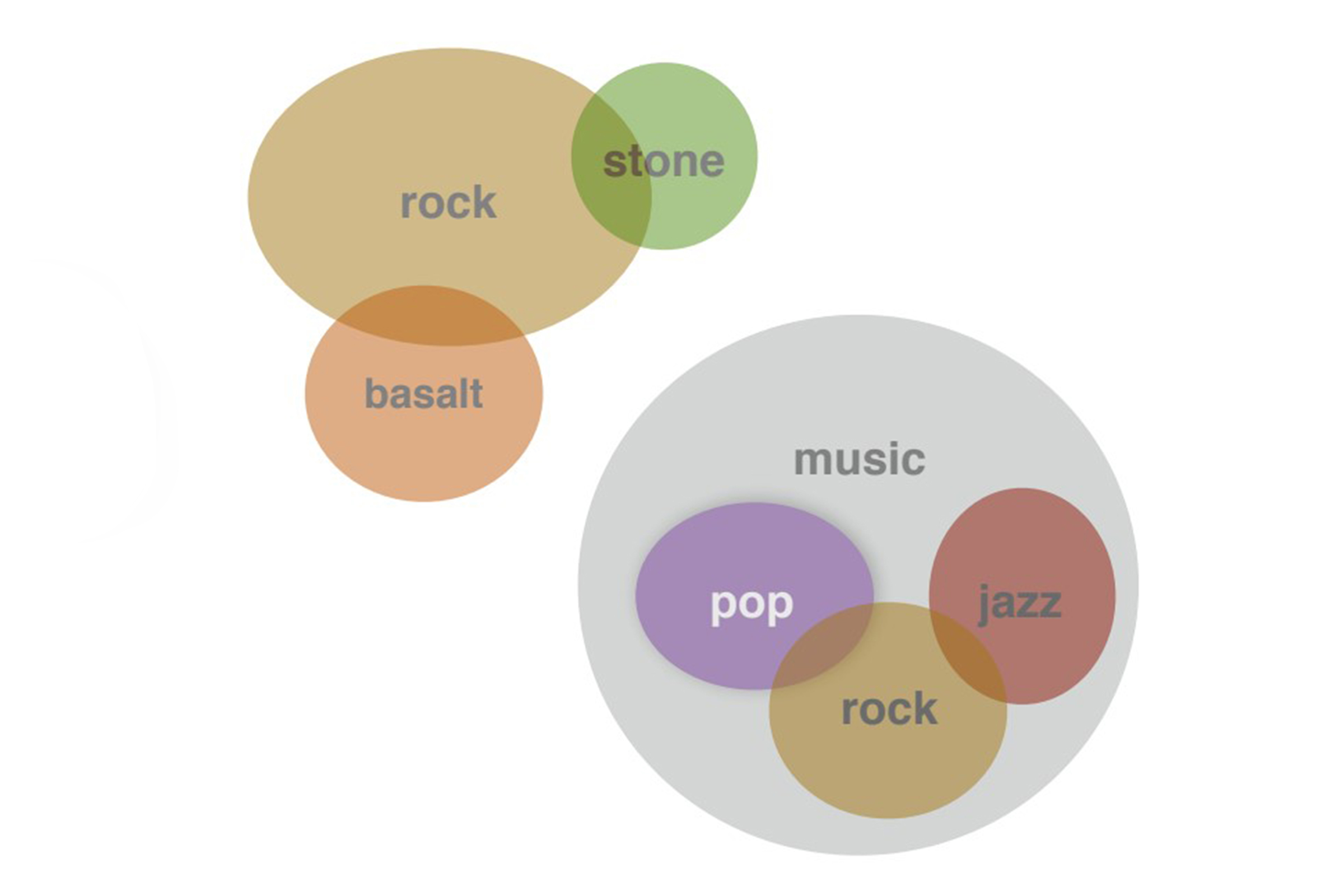
Word embeddings provide point representations of words containing useful semantic information. We introduce multimodal word distributions formed from Gaussian mixtures, for multiple word meanings, entailment, and rich uncertainty information. To learn these distributions, we propose an energy-based max-margin objective. We show that the resulting approach captures uniquely expressive semantic information, and outperforms alternatives, such as word2vec skip-grams, and Gaussian embeddings, on benchmark datasets such as word similarity and entailment.
Yang Li, Ben Athiwaratkun, Cicero Nogueira dos Santos, Bing Xiang
Generalization is a central problem in machine learning, especially when data is limited. Using prior information to enforce constraints is the principled way of encouraging generalization. In this work, we propose to leverage the prior information embedded in pretrained language models (LM) to improve generalization for intent classification and slot labeling tasks with limited training data. Specifically, we extract prior knowledge from pretrained LM in the form of synthetic data, which encode the prior implicitly. We fine-tune the LM to generate an augmented language, which contains not only text but also encodes both intent labels and slot labels. The generated synthetic data can be used to train a classifier later. Since the generated data may contain noise, we rephrase the learning from generated data as learning with noisy labels. We then utilize the mixout regularization for the classifier and prove its effectiveness to resist label noise in generated data. Empirically, our method demonstrates superior performance and outperforms the baseline by a large margin.
Evgenii Nikishin, Pavel Izmailov, Ben Athiwaratkun, Dmitrii Podoprikhin, Timur Garipov, Pavel Shvechikov, Dmitry Vetrov, Andrew Gordon Wilson
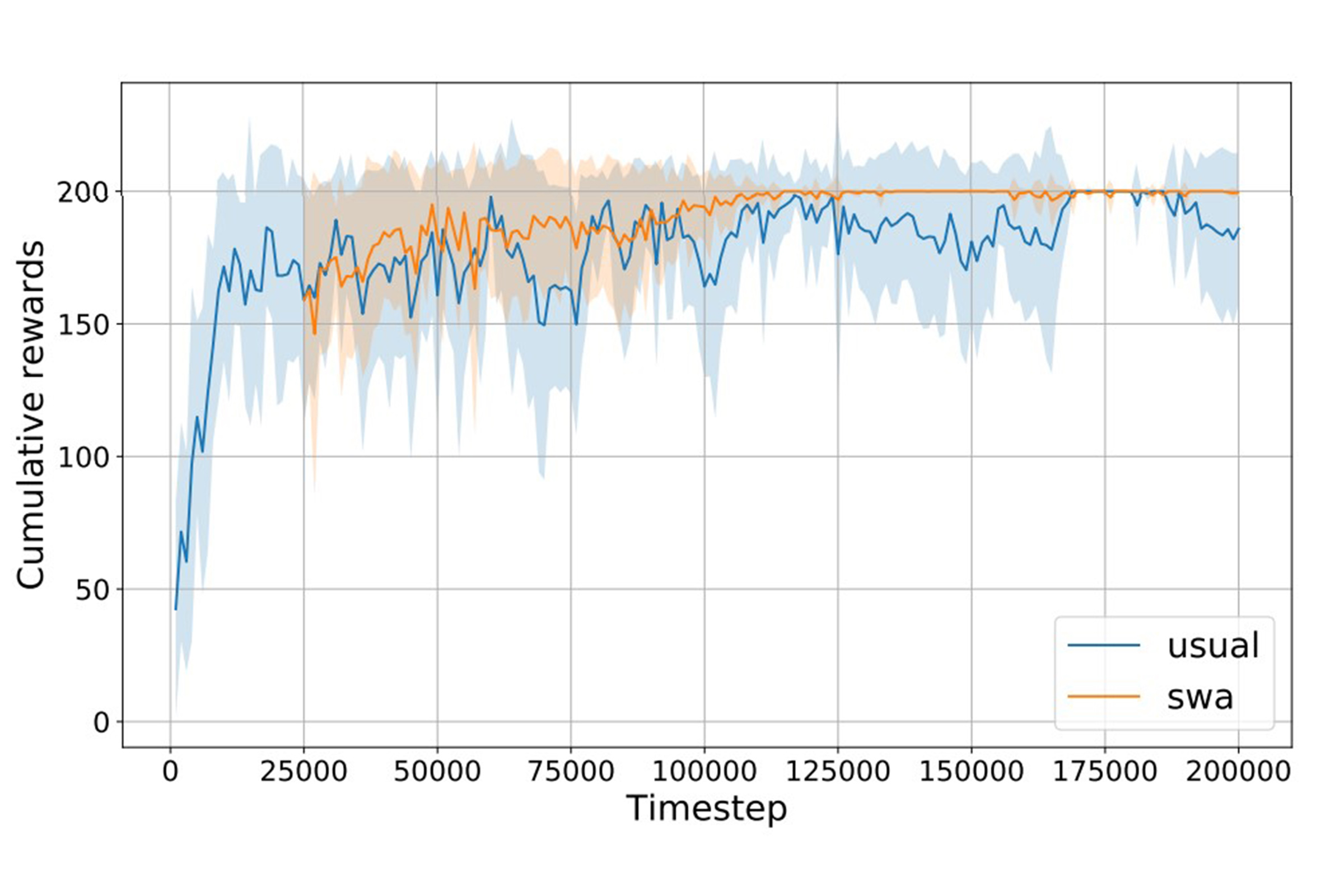
Deep reinforcement learning (RL) methods are notoriously unstable during training. In this paper, we focus on model-free RL algorithms where we observe that the average reward is unstable throughout the learning process and does not increase monotonically given more training steps. Furthermore, a highly rewarded policy, once learned, is often forgotten by an agent, leading to performance deterioration. These problems are partly caused by fundamental presence of noise in gradient estimators in RL. In order to reduce the effect of noise on training, we propose to apply stochastic weight averaging (SWA), a recent method that averages weights along the optimization trajectory. We show that SWA stabilizes the model solutions, alleviates the problem of forgetting the highly rewarded policy during training, and improves the average rewards on several Atari and MuJoCo environments.
Ben Athiwaratkun, Jack W. Stokes
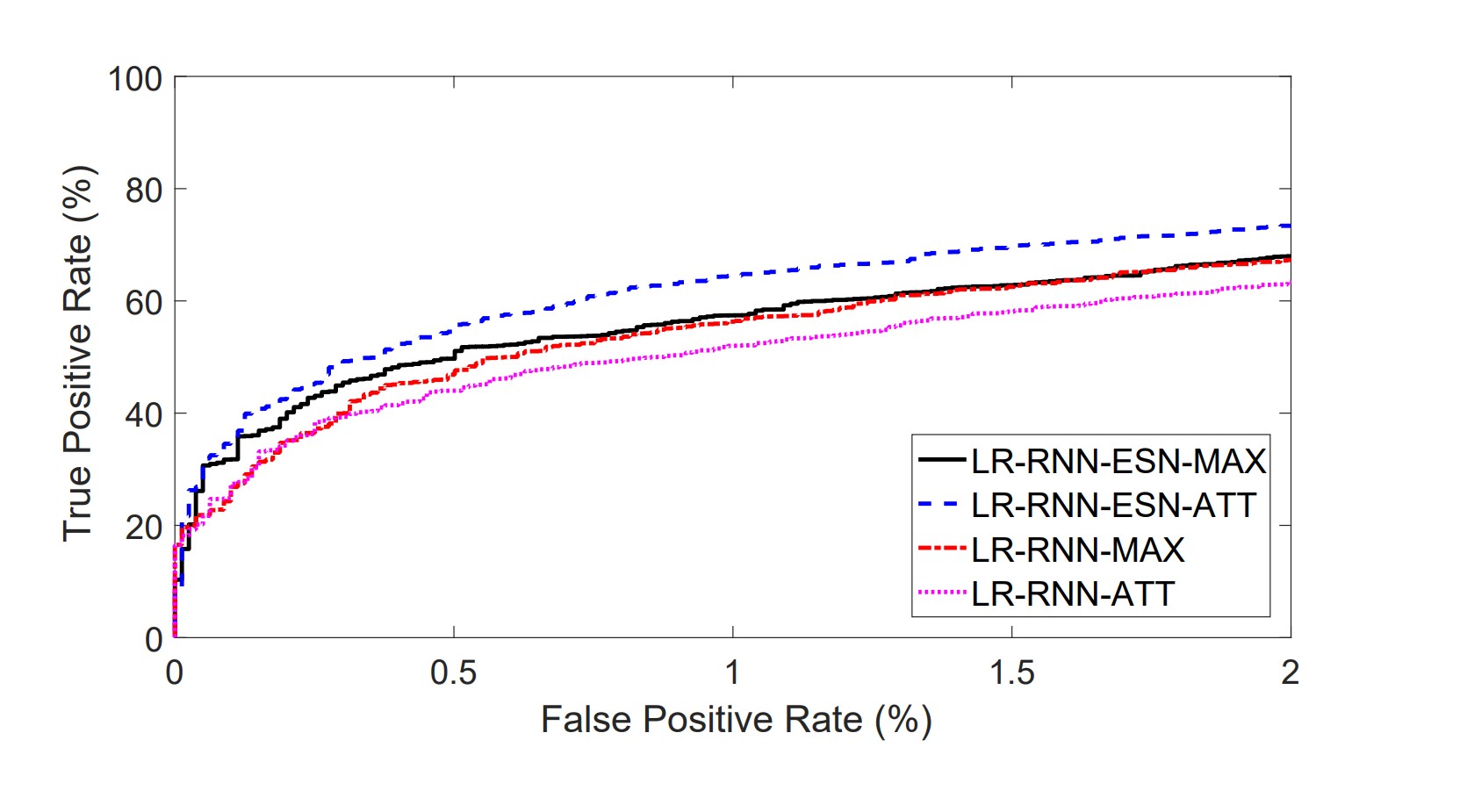
Malicious software, or malware, continues to be a problem for computer users, corporations, and governments. Previous research [1] has explored training file-based, malware classifiers using a twostage approach. In the first stage, a malware language model is used to learn the feature representation which is then input to a second stage malware classifier. In Pascanu et al. [1], the language model is either a standard recurrent neural network (RNN) or an echo state network (ESN). In this work, we propose several new malware classification architectures which include a long short-term memory (LSTM) language model and a gated recurrent unit (GRU) language model. We also propose using an attention mechanism similar to [12] from the machine translation literature, in addition to temporal max pooling used in [1], as an alternative way to construct the file representation from neural features. Finally, we propose a new single-stage malware classifier based on a character-level convolutional neural network (CNN). Results show that the LSTM with temporal max pooling and logistic regression offers a 31.3% improvement in the true positive rate compared to the best system in [1] at a false positive rate of 1%.
Index Terms— Malware Classification, Neural Language Model, LSTM, GRU, CNN

I had recently discovered machine learning and was teaching myself through online courses. As part of a Machine Learning class taught by Ryan Adams at Harvard in 2014, I was tasked with using RL to help a monkey plan its movement to avoid hitting trees and dying. Once I successfully implemented Q-learning and the monkey was able to jump without hitting any trees, I was hooked and completely enamored with the power of deep learning. At the time, some people still considered deep learning to be a passing trend, but I was convinced that it was the future.
Although this project may not seem impressive by today's standards, it marked a pivotal moment in my journey with machine learning. The class was offered online to external students through Harvard Extension School, and I was grateful for the MOOC (Massive Open Online Courses) efforts that made it possible for curious learners like myself to gain access to quality education.
In this video, we showcase the Q-Learning Algorithm's ability to train an agent to play the Swingy Monkey game. The game mechanics involve the monkey receiving a reward for successfully passing through the hoop and being penalized for hitting obstacles such as trees or the floor/ceiling. As the agent continues to play, it learns to navigate through the hoops and avoid obstacles more efficiently, leading to a noticeable improvement in scores as seen in later epochs.Problem Writeup Code
This website marked my initial attempt at making a website, which I decided to do with D3, a JavaScript library for data visualization. I invite you to play around with it, although I must admit that it is not particularly user-friendly, which is why I have deprecated it. Nonetheless, I have decided to keep it available here because I still appreciate its coolness factor. The bubble bursting effect is my favourite part.
At its core, the website is a simple concept. It represents all of its data, including project hierarchies, as a tree that is stored in a simple JSON file. The script then uses D3 to render this tree as hierarchical bubbles that can be clicked on to navigate further down the tree. Users can traverse back up the tree by clicking the small back button. In effect, the website navigation is a tree traversal!
Ben Athiwaratkun , Cesar E. Silva
We explore two properties of infinite measure preserving transformations. We examine a T that is recurrent but not 2-recurrent which implies that T x T is not conservative. We have added a proof that T x T^2 is also not conservative. In addition, we introduce conditions that imply power weak mixing property for cutting and stacking transformations with arbitrary number of cuts and tower spacers.
This thesis was subsequently published as part of the following paper (link).
Studied the effects of taxes on output, unemployment rate, household utility, and energy consumption via Computable General Equilibrium (CGE) Model. Developed an approach to minimize energy consumption and unemployment rate for a given reduction level of household utility, using the CGE model and numerical optimization with Matlab.
Found that to reduce energy consumption by means of tax imposition, it is optimal to increase taxes on primary energy and energy intensive industries.
This project is to optimize the calculation of computer generated holograms, which could be used to holographically control the path of laser beams. The constraint of the hologram is that only the phase can be adjusted, not the amplitude. The inverse Fourier Transform of a desired pattern without amplitude variations, which represents the phase-only hologram, does not capture all information and consequently there are undesired spots generated from the phase-only hologram, in addition to the original pattern.
We found that randomizing the phase of the desired grid patterns before inverse Fourier Transform can improve the image quality.Research was done under the supervision of Professor Ward Lopes at Williams College. A few unorganized scripts in Mathematica can be found here: diffraction pattern, general traps, grid trap calculation, grid trap inverse fourier transform.
Proton-proton collisions can generate clusters of particles where detection of such particles is typically challenging. The goal of this study is to be able to identify multiple top quark mass eigenstates that could be the result of proton-proton collision at the Large Hadron Collider.
We used Monte Carto simulation package in Fortran to simulate the LHC data, and analyzed the distribution of transverse masses mT2 in order to infer if we would be able to detect the top quarks, if there were present. We succeeded in distinguishing two top quark mass eigenstates with resolution of 100 MeV.
Duties included programming with Fortran and Mathematica and analyzing statistical distributions of relativistic variables. Research was done under the supervision of Professor David Tucker Smith at Williams College.
Photo credit: Top Quark, Wikipedia .
I discovered my passion for Physics in high school. I went through multiple rounds of local competitions in Thailand and eventually got the chance to compete in the International Physics Olympiad as one of the country's representatives. I have always been thankful for such a pivotal moment in my life. If it weren't for this moment, I may never have had the opportunity of coming to the US for college.
The competition itself was fun, even though a bit stressful. Each country sent a team of 5 to Isfahan (Iran) who hosted the international competition in 2007. We were there for around a week and there were two actual exam days, where the rest were sightseeing tours for students where the professors were grading and debating scores.
The first exam day is a theoretical exam with analytic questions about black holes, mechanism of car air bag, and analysis of binary star orbits. The topics sound fancy but do not assume prior knowledge for the specifics, only a general understanding of physics, and sometimes a willingness to learn a new concept quickly, the ability to connect the dots.
The second exam day was a laboratory one. I vaguely remember that I had to heat some gas in a vial which leads to change in refraction index, and had to analyze the gas.
For the theoretical problems, one can check them out here for all International Physics Olympiad. I also participated in the Asian Physics Olympiad (exams of previous years here). The experience was quite similar and was hosted in Shanghai!
Photo credit: Neutrons in a gravitational field from IPhO 2005
© Copyright 2023, Ben Athiwaratkun. All rights reserved.