
About Me

Ben Athiwaratkun — research and technical leader specializing in frontier-model inference efficiency: speculative decoding, quantization, model architecture, routing, RL rollout efficiency, and kernel generation. Senior Director of Research at Together AI, where I built and lead the Core ML research team, focusing on turning inference-efficiency research into production systems.





Research Agenda & Highlighted Work
My recent work focuses on frontier-model inference efficiency: speculative decoding, KV-cache and weight quantization, RL rollout acceleration, agentic routing, and architecture/system co-design. These projects are selected because they shipped into production systems, improved frontier-model serving efficiency, or opened new research directions for efficient test-time compute and RL rollouts.
Speculative Decoding
World's Fastest DeepSeek-R1 Inference on NVIDIA Blackwell
Together AI blog, 2025 [blog]Independently benchmarked top-ranked inference for DeepSeek-R1-0528 on NVIDIA HGX B200, powered by in-house speculative decoding algorithms shipped directly into the production engine.
When RL Meets Adaptive Speculative Training: A Unified Training-Serving System
ICML 2026 [pdf]Unified training-serving system that co-evolves speculative drafters with the RL policy, eliminating the train/serve distribution gap that degrades spec dec under shifting policy distributions.
Beat the Long Tail: Distribution-Aware Speculative Decoding for RL Training
MLSys 2026 [pdf]Accelerates RL rollouts by targeting the long-tail of trajectory lengths that dominate wall-clock time. Allocates more aggressive speculative decoding budgets to slow trajectories. Up to 50% rollout time reduction.
ATLAS: Adaptive Speculators for Production Inference
Together AI blog, 2025 [blog]Production speculative decoding drafters that learn from live traffic with zero-downtime updates, keeping draft models aligned with shifting data distributions across multiple open-source models.
Quantization & Compression
CoQuant: Covariance-Aware Rotation for 2-bit KV Cache Quantization
Under review at NeurIPS 2026Rotates the KV cache along covariance-informed axes before 2-bit quantization, decorrelating outliers so aggressive quantization preserves quality. Complements Kitty in the 2-bit KV serving roadmap.
System-Aware 4-Bit KV-Cache Quantization for Real-World LLM Serving
Under review at COLM 2026Identifies which KV cache quantization methods actually work under real serving constraints (paged memory, fused attention, concurrency). Improves throughput via higher batch size with near-zero accuracy loss.
Kitty: Accurate and Efficient 2-bit KV Cache Quantization with Dynamic Channel-wise Precision Boost
MLSys 2026 [pdf]Pushes KV cache quantization to 2-bit with near-lossless quality by dynamically allocating higher precision to outlier channels. Direct path to next-generation low-bit memory serving.
Search Your NVFP4 Scales!
MLSys 2026Smart searching of quantization scales to close the quality gap between NVFP4 and FP8/FP16. Directly applicable to frontier model weight quantization and FP4 attention.
Routing & Multi-Model Orchestration
Squeeze Evolve: Unified Multi-Model Orchestration for Verifier-Free Evolution
Preprint, 2026 [pdf] [project]Multi-model orchestration for evolutionary inference — allocating strong vs. cheap models by marginal utility at each stage. 3x cost reduction while matching verifier-based methods.
ThunderAgent: A Simple, Fast and Program-Aware Agentic Inference System
ICML 2026 [pdf] [website]Program-aware scheduling for agentic inference — co-schedules LLM calls, KV caches, and tool execution. Increases cache hit rate and throughput across serving and RL workloads.
Architecture & Inference Algorithms
Introspective Diffusion Language Models
Under review at COLM 2026 [pdf] [project page]A new generation paradigm that bridges autoregressive and diffusion models. Uses introspective strided decoding to perform verification and generation in the same forward pass, achieving 3.1x throughput while matching AR quality.
Opportunistic Expert Activation: Batch-Aware Expert Routing for Faster Decode Without Retraining
ICML 2026 [pdf]Batch-aware expert routing for MoE models that accelerates decode latency without retraining — exploits routing structure across concurrent requests in production serving.
Ladder-Residual
ICML 2025 [pdf]Redesigns residual connections to overlap communication and computation in tensor parallelism. 29% inference speedup for 70B models across 8 GPUs.
Bifurcated Attention: Accelerating Massively Parallel Decoding with Shared Prefixes in LLMs
ICML 2024 [pdf]Splits attention into shared-prefix and per-sequence GEMMs to eliminate redundant memory IO. Crucial for massively parallel sampling and RL rollouts where thousands of candidate answers are sampled for verification and reward signaling.
Experience
Publications
2026
Squeeze Evolve: Unified Multi-Model Orchestration for Verifier-Free Evolution [project]
Multi-model orchestration for evolutionary inference that allocates strong vs. cheap models based on marginal utility. Reduces API cost by ~3x and increases throughput by ~10x while matching or exceeding verifier-based methods.
CARE: Covariance-Aware and Rank-Enhanced Decomposition for Enabling Multi-Head Latent Attention — ICLR 2026
Activation-aware method for converting GQA models to MLA format. Reduces perplexity by up to 215x over naive SVD baselines at matched KV-cache budgets, and fully recovers original accuracy with brief fine-tuning.
V₁: Unifying Generation and Self-Verification for Parallel Reasoners
Replaces pointwise scoring with pairwise self-verification for test-time scaling. Improves Pass@1 by up to 10% on code and math benchmarks while being more compute-efficient than existing methods.
Aurora: When RL Meets Adaptive Speculative Training — ICML 2026
Continuously trains speculative decoding drafters from live inference traces using asynchronous RL. Supports day-0 deployment with 1.5x speedup and graceful adaptation to domain drift, with zero-downtime hot-swapping.
ThunderAgent: A Simple, Fast and Program-Aware Agentic Inference System [website] — ICML 2026
Program-aware system that co-schedules LLM inference and tool execution, achieving 1.5-3.6x throughput in serving, 1.8-3.9x in RL rollouts, and up to 4.2x disk memory savings.
When Does Divide and Conquer Work for Long Context LLM? — ICLR 2026
Theoretical framework decomposing long-context failures into task, model, and aggregator noise. Explains when chunking + weak models beats single-shot GPT-4o, and when it doesn't.
Introspective Diffusion Language Models [project page] — under review at COLM 2026
First diffusion LM to match autoregressive quality at the same scale. Introspective strided decoding performs verification and generation in the same forward pass, achieving 3.1x higher throughput.
CoQuant: Covariance-Aware Rotation for 2-bit KV Cache Quantization — under review at NeurIPS 2026
Rotates the KV cache along covariance-informed axes before 2-bit quantization, decorrelating outliers so aggressive quantization preserves quality. Complements Kitty in the 2-bit KV serving roadmap.
System-Aware 4-Bit KV-Cache Quantization for Real-World LLM Serving — under review at COLM 2026
Identifies which KV cache quantization methods work under real serving constraints. Token-wise INT4 with block-diagonal Hadamard rotation consistently achieves the best accuracy-efficiency trade-off with zero overhead.
Search Your NVFP4 Scales! — MLSys 2026
Searching for error-minimizing block scales in NVFP4 format reduces quantization error by 26%. Improves weight PTQ by up to 7.5 points (GPQA) and enables near-lossless FP4 attention on Tensor Cores.
2025
Understanding and Steering the Cognitive Behaviors of Reasoning Models at Test-Time
Identifies specialized attention heads governing reasoning behaviors and steers them at inference time via CREST. Improves accuracy by up to 17.5% while reducing token usage by 37.6%, with no training required.
CDLM: Consistency Diffusion Language Models For Faster Sampling
Accelerates diffusion language models by 3.6-14.5x through consistency modeling and block-wise causal attention enabling KV caching, while maintaining competitive accuracy on math and coding tasks.
Kitty: Accurate and Efficient 2-bit KV Cache Quantization — MLSys 2026
Near-lossless 2-bit KV cache quantization via algorithm-system co-design. Cuts KV memory by ~8x with negligible accuracy loss, enabling up to 8x larger batches and 2.1-4.1x higher throughput.
Beat the Long Tail: Distribution-Aware Speculative Decoding for RL Training — MLSys 2026
Targets the long-tail of RL rollout trajectory lengths that dominate wall-clock time. Builds adaptive drafters from historical rollouts and allocates more aggressive speculation to slow trajectories, reducing rollout time by up to 50%.
Intelligence per Watt: Measuring Intelligence Efficiency of Local AI
Local LMs can accurately answer 88.7% of real-world queries. Intelligence-per-watt improved 5.3x from 2023-2025, and local accelerators achieve at least 1.4x better efficiency than cloud counterparts.
Opportunistic Expert Activation: Batch-Aware Expert Routing for Faster Decode — ICML 2026
Dynamically re-routes tokens to piggyback on already-loaded MoE experts in the same batch. Reduces MoE layer decode latency by up to 39% with no accuracy loss and no retraining.
Staircase Streaming for Low-Latency Multi-Agent Inference
Begins final response generation from partial intermediate outputs in multi-agent pipelines. Reduces time-to-first-token by up to 93% while maintaining response quality.
Imitate Optimal Policy: Prevail and Induce Action Collapse in Policy Gradient — ICLR 2026
Discovers "Action Collapse" in policy gradient networks — a structured convergence analogous to neural collapse. Fixing the action layer to a simplex ETF yields faster and more robust RL training.
Data Diversification Methods In Alignment Enhance Math Performance In LLMs
Diversified-ThinkSolve generates diverse reasoning paths for preference optimization, improving math performance by up to 7.1% on GSM8K at only 1.03x compute overhead — far cheaper than MCTS (5x cost).
Shrinking the Generation-Verification Gap with Weak Verifiers — ICML 2025
Weaver ensembles multiple weak verifiers via weak supervision to approach oracle-level quality. Llama 3.3 70B + Weaver reaches 87.7% on reasoning tasks, matching o3-mini without finetuning.
Disentangling Reasoning and Knowledge in Medical Large Language Models
Separates medical QA into reasoning vs. knowledge subsets, finding only 32.8% require complex reasoning. BioMed-R1 trained on reasoning-heavy examples achieves strongest performance among similarly sized models.
Improving Model Alignment Through Collective Intelligence of Open-Source LLMs — ICML 2025
Distills collective intelligence from multiple open-source LLMs into smaller models. LLaMA-3.1-8B goes from 19.5 to 48.3 on Arena-Hard, creating a self-improving loop without proprietary dependencies.
How Well Can General Vision-Language Models Learn Medicine By Watching Videos?
Fine-tuning VLMs on 1031 hours of curated YouTube biomedical videos yields up to 98.7% improvement on video tasks. Educational videos designed for humans are a surprisingly effective training signal.
Think Deep, Think Fast: Investigating Efficiency of Verifier-free Inference-time-scaling
For reasoning models, simple majority voting is generally as good or better than sophisticated methods like best-of-N or sequential revisions. Non-reasoning models cannot close the gap even with extreme budgets.
Scaling Instruction-Tuned LLMs to Million-Token Contexts — ICLR 2025
Hierarchical synthetic data generation and step-by-step RoPE scaling enable instruction-tuned LLMs to handle up to 1M token contexts while maintaining general task performance.
Ladder-residual: Parallelism-Aware Architecture for Accelerating Large Model Inference — ICML 2025
Redesigns residual connections to overlap communication and computation in tensor parallelism. 29% end-to-end inference speedup for a 70B Transformer on 8 GPUs.
Training-Free Activation Sparsity in Large Language Models (TEAL) — ICLR 2025
Applies magnitude-based activation sparsity without any training, achieving 40-50% model-wide sparsity with up to 1.8x decoding speedup. Compatible with weight quantization for compounding gains.
2024
RedPajama: an Open Dataset for Training Large Language Models — NeurIPS 2024
Two massive open datasets: V1 reproduces LLaMA training data, V2 provides 100T+ raw web tokens with quality signals. Adopted for training Snowflake Arctic, Salesforce XGen, and AI2's OLMo.
Reasoning in Token Economies: Budget-Aware Evaluation of LLM Reasoning Strategies — EMNLP 2024
When controlling for compute budget, complex reasoning strategies (multi-agent debate, Reflexion) often fail to outperform simple chain-of-thought self-consistency. Some strategies even degrade with additional budget.
Mixture-of-Agents Enhances Large Language Model Capabilities — ICLR 2025
Layered multi-agent architecture where open-source LLMs collaboratively refine outputs. Scored 65.1% on AlpacaEval 2.0, surpassing GPT-4o's 57.5%.
Dragonfly: Multi-Resolution Zoom-In Encoding Enhances Vision-Language Models — ICLR 2025
Zooms in beyond native resolution via multi-crop sub-image features. Top-tier results among 7-8B VLMs on general and biomedical benchmarks, including 91.6% on SLAKE vs. 84.8% for Med-Gemini.
Bifurcated Attention: Accelerating Massively Parallel Decoding with Shared Prefixes in LLMs — ICML 2024
Splits attention into two GEMMs for shared-prefix and per-sequence KV caches, eliminating redundant memory IO. Over 2.1x speedup at 16 sequences, 6.2x at 32 sequences.
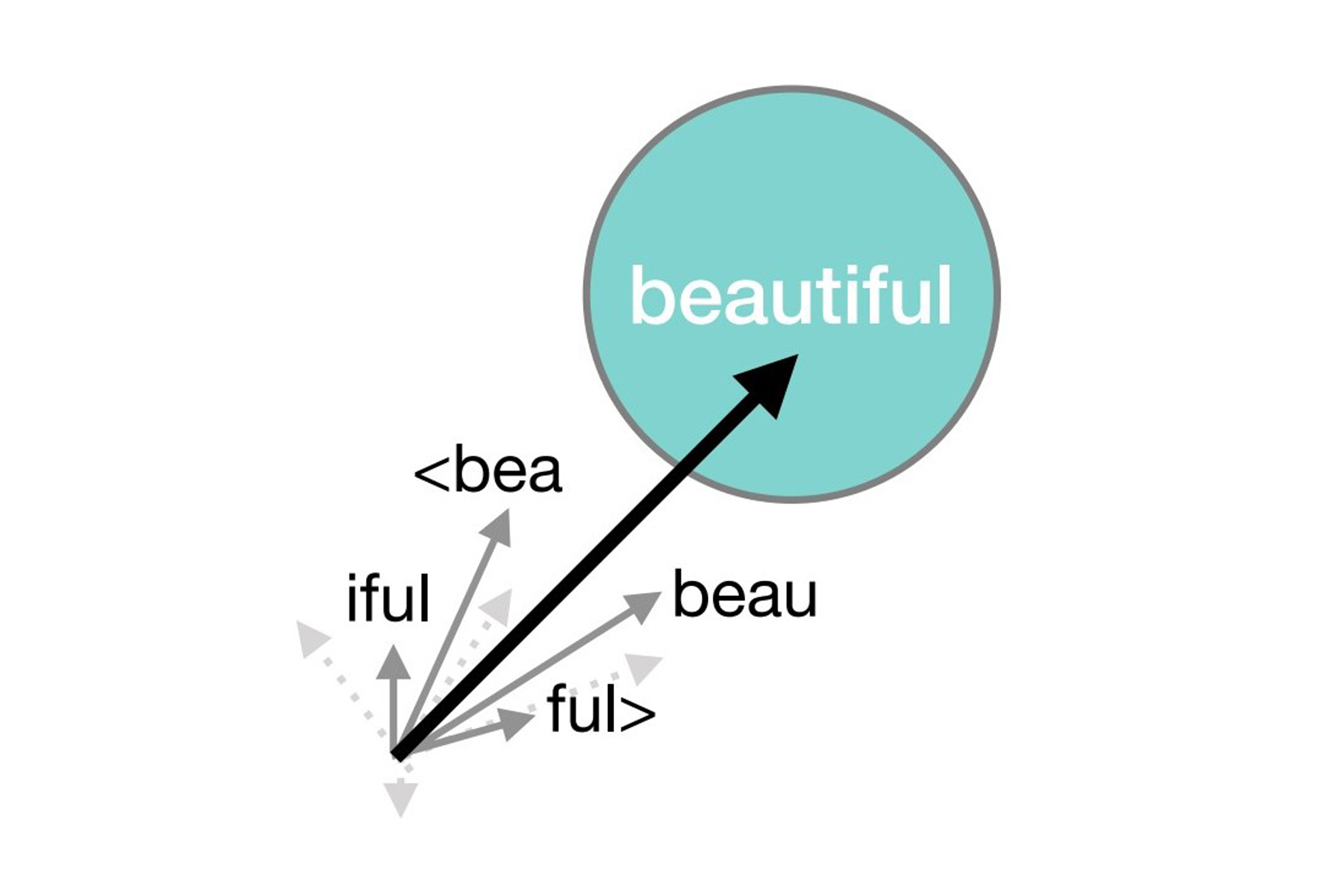
Token Alignment via Character Matching for Subword Completion — ACL 2024 (Findings)
Fixes tokenization artifacts in code/text completion by backtracking to the last complete token boundary and constraining generation to match the prompt character-by-character.
For earlier publications, see Google Scholar.





© Copyright 2023, Ben Athiwaratkun. All rights reserved.